4. 신경망 학습
학습이란 훈련 데이터로부터 가중치 매개변수의 최적값을 자동으로 획득하는 것을 뜻한다.
4장에서는 신경망이 학습할 수 있도록 해주는 지표인 손실 함수를 다뤄본다.
손실 함수의 결괏값을 가장 작게 만드는 가중치 매개변수를 찾는 것이 학습의 목표다.
이번 장에서는 손실 함수의 값을 가급적 작게 만드는 기법으로 함수의 기울기를 활용하는 경사법을 살펴본다.
4.1. 데이터에서 학습한다.
신경망의 특징은 데이터를 보고 학습할 수 있다는 점이다.
데이터에서 학습한다는 것은 가중치 매개변수의 값을 데이터를 보고 자동으로 결정한다는 뜻이다.
실제 신경망에서 매개변수를 수작업으로 정한다는 것은 불가능하다.
신경망 학습에 대해 살펴보고 파이썬으로 MNIST 데이터셋의 손글씨 숫자를 학습하는 코드를 구현해본다.
4.1.1. 데이터 주도학습
기계학습은 데이터가 생명이다. 데이터가 이끄는 접근 방식 덕에 사람 중심 접근에서 벗어날 수 있다.
기계학습에서는 사람의 개입을 최소화하고 수집한 데이터로부터 패턴을 찾으려 시도한다.
신경망과 딥러닝은 기존 기계학습보다 사람의 개입을 더욱 배제할 수 있게 해준다.
예를 들어 손글씨로 작성된 '5'라는 숫자를 인식하는 프로그램을 구현한다고 생각해보자.
사람마다 버릇이 달라 '5'를 특징짓는 규칙을 찾기 쉽지 않을 것이다.
'5'를 인식하는 알고리즘을 설계하기 보다는 이미지에서 특징(feature)을 추출하고 그 특징의 패턴을 기계학습 기술로 학습하는 방법이 좋다. 無로부터 알고리즘을 설계하는 것보다 효율이 높다.
여기서의 특징은 입력 데이터(입력 이미지)에서 본질적인 데이터(중요한 데이터)를 정확하게 추출할 수 있도록 설계된 변환기를 가리킨다.
이미지의 특징은 보통 벡터로 기술하고, 컴퓨터 비전 분야에서는 SIFT, SURF, HOG 등의 특징을 많이 사용한다.
이런 특징을 사용하여 이미지 데이터를 벡터로 변환하고, 변환된 벡터를 갖고 지도 학습 방식의 대표 분류 기법인 SVM, KNN 등으로 학습할 수 있다.
다만, 이미지를 벡터로 변환할 때 사용하는 특징은 여전이 '사람'이 설계하는 것에 주의한다.
특징과 기계학습을 활용한 접근에도 문제에 따라서는 '사람'이 적절한 특징을 생각해내야 한다.
예를 들어 개의 얼굴을 구분하려 할 때는 숫자 인식과 다른 특징을 '사람'이 생각해야 할지도 모른다.
반면 신경망(딥러닝) 방식은 아래처럼 사람이 개입하지 않는 블록 하나로 그려진다.

신경망은 이미지를 있는 그대로 학습한다.
두 번째 접근 방식(특징과 기계학습 방식)에서는 특징을 사람이 설계했지만, 신경망은 이미지에 포함된 중요한 특징까지도 '기계'가 스스로 학습할 것이다.
딥러닝을 종단간 기계학습(end-to-end machine learning)이라고 한다. 종단간은 '처음부터 끝까지'라는 의미로, 데이터(입력)에서 목표한 결과(출력)를 사람의 개입없이 얻는다는 뜻을 담고 있다.
즉, 신경망은 주어진 데이터를 온전히 'end-to-end'로 학습하고, 주어진 문제의 패턴을 발견하려 시도한다.
4.1.2. 훈련 데이터와 시험 데이터
신경망 학습에 앞서 기계학습에서 데이터 취급에 주의할 점이 있다.
기계학습 문제는 데이터를 훈련 데이터(training data)와 시험 데이터(test data)로 나눠 학습과 실험을 수행한다.
우선 훈련 데이터만 사용하여 학습하면서 최적의 매개변수를 찾는다.
이후 시험 데이터를 사용하여 앞서 훈련한 모델의 실력을 평가한다.
우리가 원하는 것은 범용적으로 사용할 수 있는 모델인데, 범용 능력을 평가하기 위해서는 훈련 데이터와 시험 데이터를 분리해야 한다.
범용 능력은 아직 보지 못한 데이터(훈련 데이터에 포함되지 않는 데이터)로도 문제를 올바르게 풀어내는 능력이다.
이 범용 능력을 획득하는 것이 기계학습의 최종 목표다.
수중에 있는 훈련 데이터만 잘 판별한다면 다른 데이터셋에는 엉망인 일도 벌어진다.
참고로 한 데이터셋에만 지나치게 최적화된 상태를 오버피팅(overfitting)이라고 한다.
overfitting은 과적합, 과대적합, 과학습, 과적응 등 다양하게 번역된다. 이 책에서는 음차표기 됐다.
한쪽 이야기(특정 데이터셋)만 너무 많이 들어서 편견이 생겨버린 상태라고 이해하면 된다.
4.2. 손실 함수
신경망 학습에서는 현재의 상태를 '하나의 지표'로 표현한다.
그 지표를 가장 좋게 만들어주는 가중치 매개변수의 값을 탐색하는 것이다.
신경망 학습에서 사용하는 지표는 손실 함수(loss function)라고 한다.
손실 함수는 일반적으로 오차제곱합과 교차 엔트로피 오차를 사용한다.
손실 함수는 신경망 성능의 '나쁨'을 나타내는 지표로, 현재의 신경망이 훈련 데이터를 얼마나 잘 처리하지 '못' 하느냐를 나타낸다. '성능 나쁨'을 지표로 하는게 부자연스럽다고 생각될 수 있지만, 손실 함수에 마이너스만 곱하면 '얼마나 좋으냐'라는 지표로 변신한다.
4.2.1. 오차제곱합
가장 많이 쓰이는 손실 함수는 오차제곱합(sum of squares for error, SSE)이다.
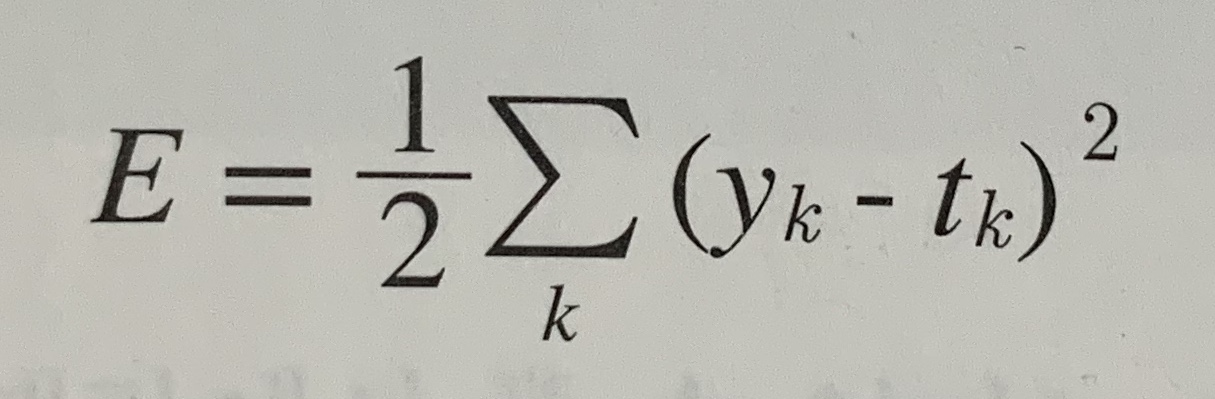
여기서 yk는 신경망의 출력(신경망이 추정한 값), tk는 정답 레이블, k는 데이터의 차원 수를 나타낸다.
이를테면 3.6. 손글씨 숫자 인식 예에서 yk와 tk는 다음과 같은 원소 10개짜리 데이터이다.
y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0]
t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]이 배열들의 원소는 첫 번째 인덱스부터 순서대로 숫자 '0', '1', '2', ...일 때의 값이다.
여기서 신경망의 출력 y는 소프트맥스 함수의 출력이다.
소프트맥스 함수의 출력은 확률로 해석할 수 있으므로, 이 예에서는 이미지가 '0'일 확률은 0.1, '1'일 확률은 0.05라고 해석된다.
정답 레이블 t는 정답을 가리키는 위치의 원소는 1로, 그 외에는 0으로 표기한다(원-핫 인코딩).
오차제곱합은 각 원소의 출력(추정 값)과 정답 레이블(참 값)의 차(yk-tk)를 제곱한 후, 그 총합을 구한다.
def sum_squares_error(y, t):
return 0.5 * np.sum((y-t)**2)sum_squares_error 함수의 인수 y와 t는 넘파이 배열이다.
이 함수를 실제로 사용해보겠다.
#정답은 '2'
t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
#예1 : '2'일 확률이 가장 높다고 추정함 (0.6)
y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0]
sum_squares_error(np.array(y), np.array(t)) #0.09750000000000003
#예2 : '7'일 확률이 가장 높다고 추정함 (0.6)
y = [0.1, 0.05, 0.1, 0.0, 0.05, 0.1, 0.0, 0.6, 0.0, 0.0]
sum_squares_error(np.array(y), np.array(t)) #0.5975첫 번째의 예는 정답이 '2'고 신경망의 출력도 '2'에서 가장 높은 경우다.
두 번째 예에서는 정답은 똑같이 '2'지만, 신경망의 출력은 '7'에서 가장 높다.
이 실험의 결과로 첫 번째 예의 손실 함수 쪽 출력이 작으며 정답 레이블과의 오차도 작은 것을 알 수 있다.
오차제곱합 기준으로는 첫 번째 추정 결과가 정답에 더 가깝다고 판단할 수 있다.
4.2.2. 교차 엔트로피 오차
다른 손실 함수로서 교차 엔트로피 오차(cross entropy error, CEE)도 자주 이용한다.
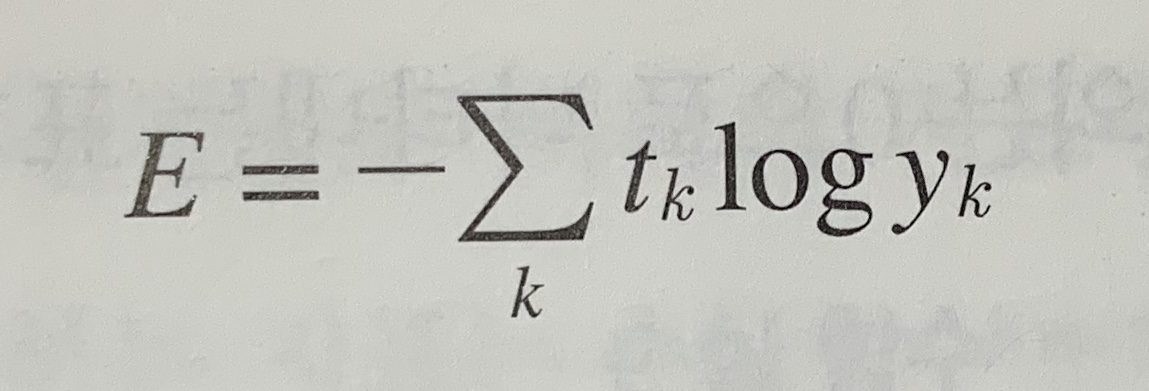
여기서 log는 밑이 e인 자연로그(log e)다. yk는 신경망의 출력, tk는 정답 레이블이다.
또 tk는 정답에 해당하는 인덱스의 원소만 1이고 나머지는 0이다(원-핫 인코딩).
그래서 위의 식은 정답일 때의 추정(tk가 1일 때의 yk)의 자연로그를 계산하는 식이 된다.
정답이 아닌 나머지 모두는 tk가 0이므로 log yk와 곱해서 0이 되어 결과에 영향을 주지 않는다.
교차 엔트로피 오차는 정답일 때의 출력이 전체 값을 정한다.
예를 들어 정답 레이블은 '2'가 정답이라 하고 이때의 신경망 출력이 0.6이라면 교차 엔트로피 오차는 -log0.6 = 0.51 이다.
아래는 자연로그 그래프다.

x가 1일 때 y는 0이 되고 x가 0에 가까워질수록 y의 값은 점점 작아진다.
정답에 해당하는 출력이 커질수록 0에 다가가다가, 그 출력이 1일 때 0이 된다.
정답일 때의 출력이 작아질수록 오차는 커진다.
교차 엔트로피 오차를 구현해본다.
def cross_entropy_error(y, t):
delta = 1e-7
return -np.sum(t * np.log(y + delta))y와 t는 넘파이 배열이다.
마지막에 작은 값 delta를 더했다. np.log() 함수에 0을 입력하면 마이너스 무한대 -inf가 되어 더 이상 계산을 할 수 없게 되기 때문이다. 이를 방지했다.
t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0]
cross_entropy_error(np.array(y), np.array(t)) #0.510825457099338
y = [0.1, 0.05, 0.1, 0.0, 0.05, 0.1, 0.0, 0.6, 0.0, 0.0]
cross_entropy_error(np.array(y), np.array(t)) #2.302584092994546첫 번째 예는 정답일 때의 출력이 0.6인 경우로, 이때의 교차 엔트로피 오차는 약 0.51이다.
두 번째 예는 정답일 때의 출력이 더 낮은 0.1인 경우로, 교차 엔트로피 오차는 무려 2.3이다.
오차 값이 더 작은 첫 번째 추정이 정답일 가능성이 높다고 판단한다.
4.2.3. 미니배치 학습
기계학습 문제는 훈련 데이터를 사용해 학습한다.
훈련 데이터에 대한 손실 함수의 값을 구하고, 그 값을 최대한 줄여주는 매개변수(가중치와 편향)를 찾아낸다.
이렇게 하려면 모든 훈련 데이터를 대상으로 손실 함수 값을 구해야 한다.
즉, 훈련 데이터가 100개 있으면 그로부터 계산한 100개의 손실 함수 값들의 합을 지표로 삼는 것이다.
훈련 데이터 모두에 대한 손실 함수의 합을 구하는 방법을 생각해보겠다.
교차 엔트로피 오차는 아래처럼 된다.

데이터가 N개라면 tnk는 n번째 데이터의 k번째 값을 의미한다(ynk는 신경망의 출력, tnk는 정답 레이블).
마지막에 N으로 나눔으로써 '평균 손실 함수'를 구한다.
MNIST 데이터셋은 훈련 데이터가 60000개였다. 그래서 모든 데이터를 대상으로 손실 함수의 합을 구하려면 시간이 좀 걸린다.
빅데이터 수준이 되면 훨씬 거대해지는데, 일일이 손실 함수를 구하는 것은 비현실적이다.
이런 경우 데이터 일부를 추려 전체의 '근사치'로 이용할 수 있다.
신경망 학습에서도 훈련 데이터로부터 일부만 골라 학습을 수행하고, 이 일부를 미니배치(mini-batch)라고 한다.
60000개의 훈련 데이터 중 100장을 무작위로 뽑아 학습하는 것이다. 이러한 학습 방법을 미니배치 학습이라 한다.
3장에서 처럼 load_mnist 함수로 MNIST 데이터셋을 읽어온다.
(깃허브 https://github.com/code4human/deep-learning-from-scratch 에서 dataset/mnist.py파일)
import sys, os
sys.path.append(os.pardir)
import numpy as np
from dataset.mnist import load_mnist
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
print(x_train.shape) #(60000, 784)
print(t_train.shape) #(60000, 10)훈련 데이터는 60000개고, 입력 데이터는 784열(원래는 28x28)인 이미지 데이터임을 알 수 있다.
정답 레이블은 10줄짜리 데이터다.
이 훈련 데이터에서 무작위로 10장만 빼내려면 넘파이의 np.random.choice() 함수를 쓰면 된다.
train_size = x_train.shape[0] #60000
batch_size = 10
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]np.random.choice()로 지정한 범위의 수 중에서 무작위로 원하는 개수만 꺼낼 수 있다.
np.random.choice(60000, 10)은 0 이상 60000 미만의 수 중에서 무작위로 10개를 골라낸다.
아래는 실제로 돌려본 모습이다. 이 함수가 출력한 배열을 미니배치로 뽑아낼 데이터의 인덱스로 사용하면 된다.
np.random.choice(60000, 10)
# array([48491, 47017, 55566, 19188, 28573, 28280, 22313, 53827, 57667, 59156])
4.2.4. (배치용) 교차 엔트로피 오차 구현하기
미니배치 같은 배치 데이터를 지원하는 교차 엔트로피 오차를 구현해보자.
데이터가 하나인 경우와 데이터가 배치로 묶여 입력될 경우 모두를 처리할 수 있게 하겠다.
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
return -np.sum(t * np.log(y + 1e-7)) / batch_sizey는 신경망의 출력, t는 정답 레이블이다.
y가 1차원이라면, 즉 데이터 하나당 교차 엔트로피 오차를 구하는 경우는 reshape 함수로 데이터 형상을 바꿔준다.
그리고 배치의 크기로 나눠 정규화하고 이미지 1장당 평균의 교차 엔트로피 오차를 계산한다.
원-핫 인코딩일 때 t가 0인 원소는 교차 엔트로피 오차도 0이므로 그 계산은 무시해도 좋다.
정답에 해당하는 신경망의 출력만으로 교차 엔트로피 오차를 계산할 수 있다.
아래는 reshape 메소드를 이해하기 위한 예시다.
m = np.array([1,2,3,4])
print( m) # [1 2 3 4]
print(m.shape) # (4,)
m = m.reshape(1, m.size) # m.size는 4
print(m) # [[1 2 3 4]]
print(m.shape) # (1, 4)
t = np.array([[2,2], [3,3]])
t = t.reshape(1, t.size) # t.size는 4
print(t) # [[2 2 3 3]]
print(t.shape) # (1, 4)
print(t.shape[0]) # 1
print(t.shape[1]) # 4
정답 레이블이 원-핫 인코딩이 아니라 '2'나 '7' 등의 숫자 레이블이라면 교차 엔트로피 오차는 아래처럼 구현한다.
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
return -np.sum(np.log( y[np.arange(batch_size), t] + 1e-7 )) / batch_size
원-핫 인코딩 시 t * np.log(y)였던 부분을 레이블 표현일 때는 np.log( y[np.arange(batch_size), t] )로 구현한다.
np.arange(batch_size)는 0부터 batch_size-1까지 배열을 생성한다.
t에는 레이블이 [2, 7, 0, 9, 4]와 같이 저장되어 있으므로 y[np.arange(batch_size), t] 는 각 데이터의 정답 레이블에 해당하는 신경망의 출력을 추출한다.
이 예에서는 [ y[0,2], y[1,7], y[2,0], y[3,9], y[4,4] ]인 넘파이 배열을 추출한다.
4.2.5. 왜 손실 함수를 설정하는가?
왜 '정확도'라는 지표를 두고 '손실 함수의 값'이라는 우회적인 방법을 택하는 것일까?
신경망 학습에서는 손실 함수의 값을 최소화하는 매개변수(가중치와 편향)을 찾는다.
이때 매개변수의 미분(기울기)를 계산하고 그 미분 값을 단서로 매개변수의 값을 서서히 갱신하는 과정을 반복한다.
매개변수의 손실 함수의 미분이란 "매개변수의 값을 아주 조금 변화시켰을 때, 손실 함수가 어떻게 변하나"의 의미다.
만약 이 미분 값이 음수면 그 매개변수를 양의 방향으로 변화시켜 손실 함수의 값을 줄일 수 있다.
미분값이 0이면 매개변수를 어느 쪽으로 움직여도 손실 함수의 값은 줄어들지 않는다. 그래서 매개변수 갱신은 멈춘다.
신경망을 학습할 때 정확도를 지표로 삼아서는 안 된다.
정확도를 지표로 하면 매개변수의 미분이 대부분의 장소에서 0이 되기 때문이다.
정확도는 매개변수의 미미한 변화에는 거의 반응을 보이지 않고, 반응이 있더라도 그 값이 불연속적으로 갑자기 변화한다.
예를 들어 한 신경망이 100장의 훈련 데이터 중 32장을 올바로 인식한다고 가정하자.
그럼 정확도는 32%다. 정확도가 지표라면 가중치 매개변수의 값을 조금 바꿔도 정확도는 그대로 32%일 것이다.
매개변수를 약간만 조정해서는 정확도가 개선되지 않는다. 개선되더라도 32.0123%같은 연속적 변화가 아닌 33%나 34%처럼 불연속적인 값으로 바꿔버린다.
이와 달리 손실 함수 지표는 매개변수 변화에 반응하여 0.93432처럼 연속적으로 변화한다.
이는 '계단 함수'를 활성화 함수로 사용하지 않는 이유와도 비슷하다.
계단 함수로는 신경망 학습이 잘 이뤄지지 않는다.
계단 함수의 미분은 대부분의 장소(0이외의 곳)에서 0이기 때문이다.

시그모이드 함수의 미분(접선)은 출력(세로축의 값)이 연속적으로 변하고 곡선의 기울기도 연속적으로 변한다.
기울기가 0이 되지 않는 덕분에 신경망이 올바르게 학습할 수 있는 것이다.
4.3. 수치 미분
경사법에서는 기울기(경사) 값을 기준으로 나아갈 방향을 정한다.
수치 미분은 영어로 numerical differentiation으로 표기한다.
4.3.1. 미분
미분은 '특정 순간'의 변화량을 뜻한다.
10분간의 평균 속도를 구한다면 10분을 최소의 순간(직전 1분, 직전 1초, 직전 0.1초에 달린 거리, ...)으로 줄여 순간의 변화량(순간의 속도)을 얻는다.
미분의 수식은 아래와 같다.

좌변은 f(x)의 x에 대한 미분(x에 대한 f(x)의 변화량)을 나타낸다. x의 '작은 변화'가 함수 f(x)를 얼마나 변화시키느냐의 뜻이다.
이때 시간의 작은 변화, 즉 시간을 뜻하는 h를 한없이 0에 가깝게 한다는 의미로 극한 h->0로 나타낸다.
식을 바탕으로 함수를 미분하는 계산을 구현한다. h에 작은 값을 대입해 아래처럼 계산할 수 있다.
#나쁜 구현의 예
def numerical_diff(f, x):
h = 10e-50
return (f(x + h) - f(x)) / hnumerical_diff 함수는 '함수 f'와 '함수 f에 넘길 인수 x'라는 두 인수를 받는다.
위의 함수는 개선할 점이 두 개 있다.
첫째, 앞의 구현에서는 h에 가급적 작은 값을 대입하고 싶었기에 10e-50을 이용했다. 이 값은 0.00...1 형태에서 소수점 아래 0이 49개라는 뜻이다(가수가 10이므로 50에서 1이 빠짐).
그러나 이 방식은 반올림 오차(rounding error) 문제를 일으킨다.
반올림 오차는 작은 값(가령 소수점 8자리 이하)이 생략되어 최종 계산 결과에 오차가 생기게 한다.
1e-50을 float32형(32비트 부동소수점)으로 나타내면 0.0이 된다.
너무 작은 값을 이용하면 컴퓨터로 계산하는데 문제가 된다.
np.float32(1e-50) #0.0
적당히 작은 값 h로 10의 -4제곱 정도의 값을 사용하면 좋은 결과를 얻는다고 알려져 있다.
둘째, 함수 f의 차분을 개선해야 한다. 차분이란 임의 두 점에서의 함수 값들의 차이를 말한다.
앞의 구현에서는 x + h와 x 사이의 함수 f의 차분을 계산하고 있지만, 애당초 이 계산에는 오차가 있다.
'진정한 미분'은 x 위치의 함수의 기울기(접선)에 해당하지만, 이번 구현에서의 미분은 (x+h)와 x 사이의 기울기다.
이 차이는 h를 무한이 0으로 좁히는 것이 불가능해 생기는 한계다.

수치 미분에는 오차가 포함된다.
이 오차를 줄이기 위해 (x+h) 와 (x-h)일 때의 함수 f의 차분을 계산하는 방법을 쓰기도 한다.
이 차분은 x를 중심으로 그 전후의 차분을 계산한다는 의미에서 중심 차분 혹은 중앙 차분이라 한다.
( (x+h)와 x의 차분은 전방 차분이라고 한다.)
위의 두 개선점을 적용해 수치 미분을 다시 구현해본다.
#두 개선점을 적용한 수치 미분
def numerical_diff(f, x):
h = 1e-4 #0.0001
return (f(x + h) - f(x - h)) / (2*h)여기에서 하는 것처럼 아주 작은 차분으로 미분하는 것을 수치 미분이라 한다.
한편 수식을 전개해 미분하는 것은 해석적(analytic)이라는 말을 이용하여 '해석적 해' 혹은 '해석적으로 미분하다' 등으로 표현한다. 가령 y = x2(x의 제곱) 은 dy/dx = 2x로 풀어낼 수 있다. 그래서 x = 2일 때 y의 미분은 4가 된다.
간단히 말해 '해석적 미분'은 우리가 수학 시간에 배운 바로 그 미분이고, '수치 미분'은 이를 '근사치'로 계산하는 방법이다.
4.3.2. 수치 미분의 예
수치 미분을 사용하여 간단한 함수를 미분해본다.

def function_1(x):
return 0.01*x**2 + 0.1*x
이 함수를 그려본다.
import numpy as np
import matplotlib.pylab as plt
x = np.arange(0.0, 20.0, 0.1) #0에서 20까지 0.1 간격의 배열 x를 만든다(20은 미포함).
y = function_1(x)
plt.xlabel("x")
plt.ylabel("f(x)")
plt.plot(x, y)
plt.show()
이 함수에서 x = 5일 때와 10일 때 미분을 계산해본다.
print(numerical_diff(function_1, 5)) #0.1999999999990898
print(numerical_diff(function_1, 10)) #0.2999999999986347계산한 미분 값이 x에 대한 f(x)의 변화량이다. 즉, 함수의 기울기다.
함수 function_1의 해석적 해는 df(x) / dx = 0.02x + 0.1 이다.
그래서 x가 5와 10일 떄의 '진정한 미분'(해석적 미분)은 0.2와 0.3이다.
앞의 수치 미분과 비교하면 그 오차가 매우 작다.
수치 미분 값을 기울기로 하는 직선을 그려보면 함수의 접선에 해당한다.
import numpy as np
import matplotlib.pylab as plt
def numerical_diff(f, x):
h = 1e-4 # 0.0001
return (f(x+h) - f(x-h)) / (2*h)
def function_1(x):
return 0.01*x**2 + 0.1*x
def tangent_line(f, x):
d = numerical_diff(f, x)
print(d)
y = f(x) - d*x
return lambda t: d*t + y
x = np.arange(0.0, 20.0, 0.1)
y = function_1(x)
plt.xlabel("x")
plt.ylabel("f(x)")
tf = tangent_line(function_1, 10)
y2 = tf(x)
plt.plot(x, y)
plt.plot(x, y2)
plt.show()
4.3.3. 편미분
편미분이란 변수가 여럿인 함수에 대한 미분이다.
아래는 인수들의 제곱 합을 계산하는 식이다.

def function_2(x):
return x[0]**2 + x[1]**2
#또는 return np.sum(x**2)인수 x는 넘파이 배열이라고 가정한다. 각 원소를 제곱하고 그 합을 구하는 이 함수를 그래프로 그리면 3차원이다.
식을 미분해볼텐데 변수가 2개라는 것에 주의한다. x0 와 x1 중 어느 변수에 대한 미분이냐를 구별한다.

편미분을 구하는 방법은 아래와 같다.
#x0 = 3, x1 = 4 일 때 x0에 대한 편미분
def function_tmp1(x0):
return x0*x0 + 4.0**2.0
print( numerical_diff(function_tmp1, 3.0) ) #6.00000000000378
#x0 = 3, x1 = 4 일 때 x1에 대한 편미분
def function_tmp2(x1):
return 3.0**2.0 + x1*x1
print( numerical_diff(function_tmp2, 4.0) ) #7.999999999999119변수가 하나인 함수를 정의하고, 그 함수를 미분하는 형태로 구현했다.
첫 번째는 x1 = 4로 고정된 새로운 함수를 정의하고 변수가 x0 하나뿐인 함수에 대해 수치 미분 함수를 적용했다.
해석적 미분의 결과와 거의 같다.
편미분은 변수가 하나인 미분과 마찬가지로 특정 장소읙 기울기를 구한다.
단, 여러 변수 중 목표 변수 하나에 초점을 맞추고 다른 변수는 값을 고정한다.
4.4. 기울기 부터는 다음 포스팅에 이어서 작성한다.
<참고 문헌>
사이토 고키(2019), 『밑바닥부터 시작하는 딥러닝』, 한빛미디어, pp.107-127.
'Study > 책『밑바닥부터 시작하는 딥러닝』' 카테고리의 다른 글
| 5-1. 오차역전파법 (0) | 2020.03.31 |
|---|---|
| 4-2. 신경망 학습 (0) | 2020.03.25 |
| 3-2. 신경망 (0) | 2020.03.09 |
| 보충) numpy 행렬의 형상 차이 - (N,) (N,1)(1,N) (0) | 2020.03.08 |
| 3-1. 신경망 (0) | 2020.03.07 |




댓글